
Comment Triage Demo: Ollama LLMs in Institutional CMS Workflows
I built this proof of concept to see how a local Large Language Model (LLM) can assist institutional CMS workflows without sending data off-prem. The scope was intentionally limited to clarity, auditability, and explicit human control.
Goal
The objective was reduction of manual review effort without transferring decision authority to the model. The system generates summaries, labels, and draft responses. Final decisions remain with staff.
What the demo does
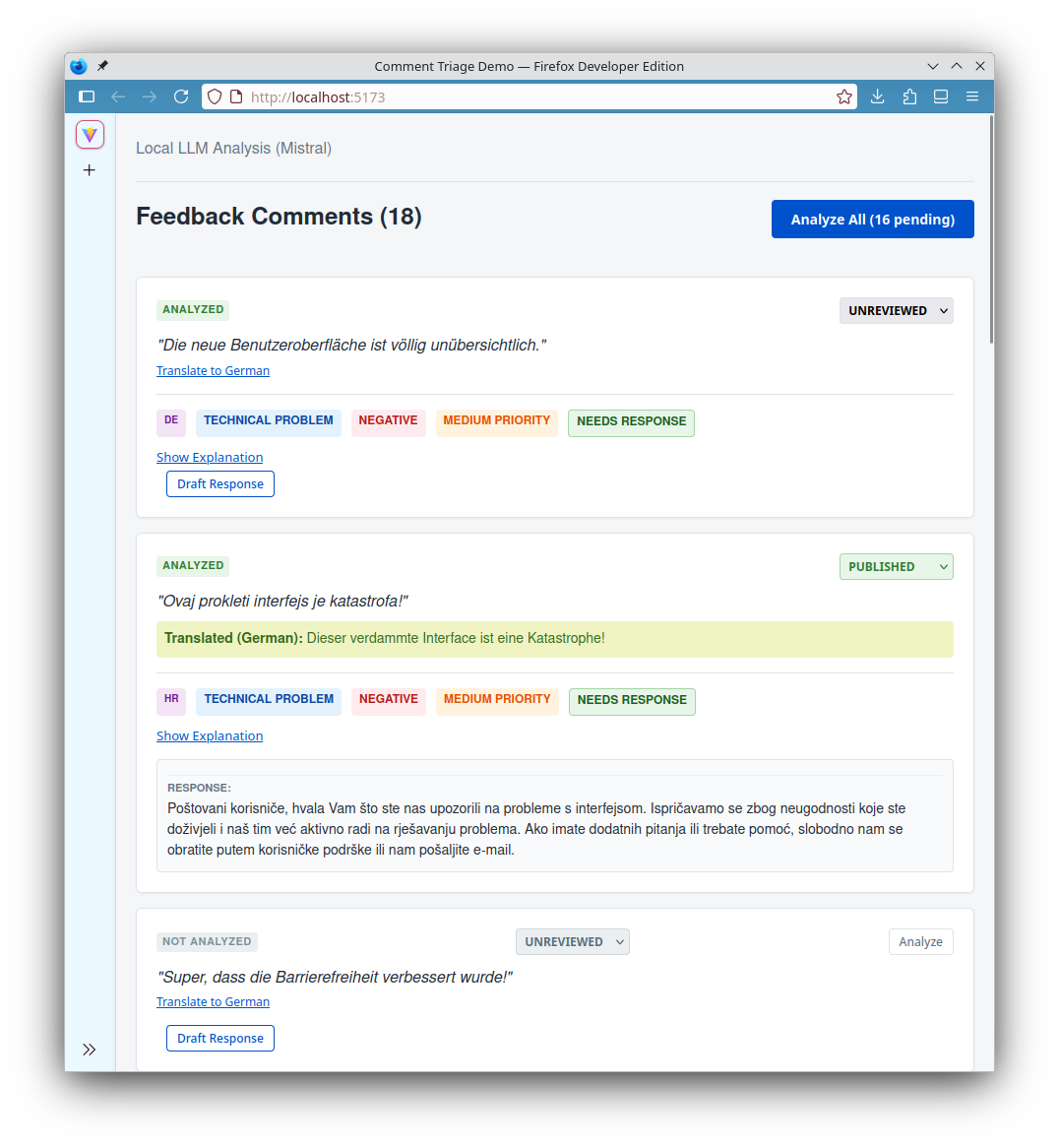
- The demo categorizes and analyzes incoming comments
- It returns short explanations for each classification
- It translates comments to German
- It drafts response suggestions
Why local LLMs
I chose a local model (Ollama + mistral-7b) to keep sensitive content on the same machine and avoid external API dependencies. This guarantees full data ownership and avoids third-party exposure.
Implementation notes
- Backend: PHP (simple HTTP API)
- Frontend: React + Vite
- Model runtime: Ollama with the
mistral-7bmodel
What happens in the code
The app seeds a local SQLite database with multilingual sample comments so the UI has data on first run. The PHP API exposes endpoints to list comments, analyze one or all comments, generate a draft response, translate a comment, save a review status, and reset the demo data. Analysis sends only the id and text to Ollama’s chat API with a JSON schema, then stores language, topic, sentiment, urgency, response need, inappropriate-content flags, and a short explanation. The React UI loads comments, runs analysis sequentially to avoid timeouts, shows tags and optional reasoning, supports German translation, and lets staff draft and save a response with a human confirmation checkbox.
What I learned
Deployment of an open-source LLM on local hardware is technically trivial.
A local LLM can reduce the manual burden of comment review while preserving privacy and human oversight. It also surfaces the limits: mistral on an underpowered device is slower, can miss nuance, and translation quality varies across languages. Smaller models also struggle with longer context, edge cases, and consistency. With a dedicated server and stronger hardware, a larger model with more context window and parameters would mitigate most of these issues while keeping the same workflow intact.
But the system’s behavior ultimately rests on the alignment baked into the model during training. A transformer model is a black box. I cannot feasibly inspect or modify its internal state in detail. For this reason, a human has to check the results and full automation still is to risky for now.
A part of this problem often is humorously illustrated by the “shoggoth with a smiley face” meme:
